
In my last article, Becoming a data-driven enterprise: From Data Warehouse to the Data Lake, I discussed the evolution of BI tools and data lakes from the 1990s to present day, driven by the potential for gaining insights and improving decision-making. The article noted the explosive growth of data and the evolution of machine learning and AI tools. I argued that the history of modern computing swings between centralized and decentralized approaches and asked the question whether “the concept of microservices can be applied to data analytics as a reaction to big data and data lakes.”
My own experience working with data products in the 1990s was domain oriented. Working on settlements of long-distance carriers in the U.S. meant that we were using a unique data set generated by a heavily regulated telecommunication service. We were naturally decentralized and created our own service-oriented architecture (SOA) of sorts. Looking back from 2023, the most apparent limitations were the inability to provide self-service and extend our analytics capabilities beyond our own team’s needs.
The emerging data lake
By the 2010s, the data lake promised to fix our old issues and open the world to new opportunities to democratize data. But in recent years we have seen that the data lake concept has a set of issues we discussed in the previous article:
a. Data governance to ensure accurate and consistent data is rigorous and expensive
b. Data security is complex and still not completely resolved making lakes a big target for hackers
c. Access control and data masking is proving difficult, which means that much of the data is never used.
d. Costs are very high as cloud storage and tool licenses are expensive and data tends to be retained for too long.
To address these challenges, companies need to take a comprehensive approach to governance, technology and security. A relatively new concept to fix these issues is the ‘data lake house’ coined by Databricks in 2020. According to databricks.com, ‘A data lakehouse unifies the best of data warehouses and data lakes in one simple platform to handle all your data, analytics and AI use cases. It’s built on an open and reliable data foundation that efficiently handles all data types and applies one common security and governance approach across all your data and cloud platforms.’ The data lake house adds meta data and governance layers to the architecture to create a single concept platform:
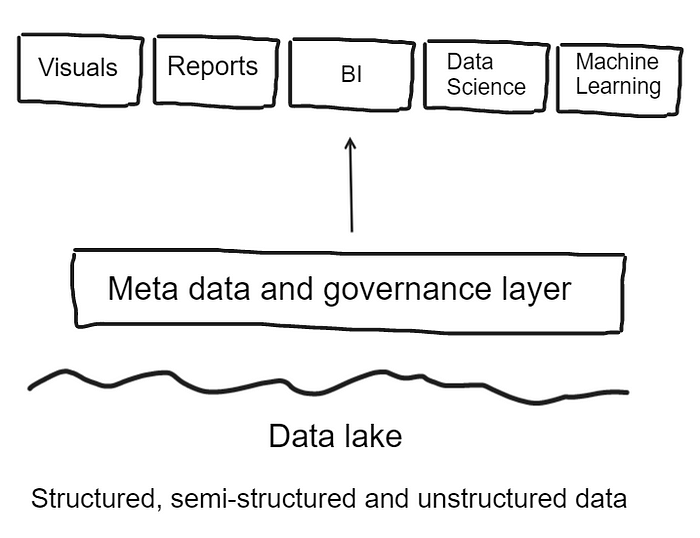
However, what seems like a never-ending escalation of systems and tools to make sense of data does not address the fundamental challenges of data collections. In an article from 2019, How to Move Beyond a Monolithic Data Lake to a Distributed Data Mesh, Zhamak Dehghani argues that:
‘Many enterprises are investing in their next generation data lake, with the hope of democratizing data at scale to provide business insights and ultimately make automated intelligent decisions. Data platforms based on the data lake architecture have common failure modes that lead to unfulfilled promises at scale. To address these failure modes we need to shift from the centralized paradigm of a lake, or its predecessor data warehouse. We need to shift to a paradigm that draws from modern distributed architecture: considering domains as the first class concern, applying platform thinking to create self-serve data infrastructure, and treating data as a product.’
A key premise of Dehghani’s argument is the presence of ‘failure modes’ in the data lake concept:
a. Centralized and monolithic
The modern data lake will ingest any type of data (unstructured/semi-structured/structured). This data can be enriched and transformed and made available to anyone in the organization. This ‘big data’ platform becomes domain-less. Enterprises typically organize a central data team that builds and maintains a central data platform that is thought to solve all issues for all data stakeholders. Prukalpa wrote an analysis of the modern data platform where she outlines the major building blocks:
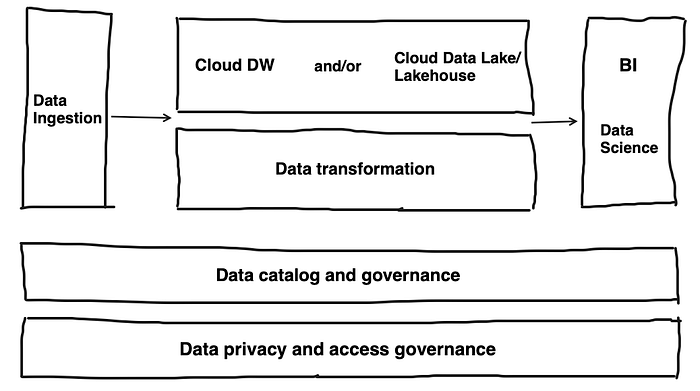
b. Coupled pipeline decomposition
A problem with the modern data platforms is what Dheghani calls ‘a coupled pipeline decomposition.’ This means that the output of stage A is coupled to the input of stage B, and so on, making it impossible to make changes at any stage without impacting the whole pipeline.
The opposite would be a decoupled composition where you use independent components that can be changed and scaled separately. Through standard interfaces and protocols, you can make the components work together seamlessly. This is how microservice architectures work to create scalability and resilience in complex systems.
Dehghani argues that we must change how we design functions like ingestion, cleansing and serving into independently deployable components. Thus, you can have independent teams that work in parallel.
c. Siloed and hyper-specialized ownership
A centralized data team is something I’ve seen in several larger corporations. The consists of highly educated data engineers and data scientists that focus on the core data, but they don’t necessarily have any domain knowledge of the business they are working in. The customer is perhaps a marketing or sales manager for a widget. They know their product and market segment, but they don’t understand what data are available and how to use data in analytics. This is the point where the dream of the data-driven company goes to die.
So now we have an architecture and an organization incapable of delivering on the promise of ubiquitous data driving the business. How can we design a concept that gets us back on track? Dehghani believes the answer is what she calls the ‘data mesh.’
The current state of data analysis
Having worked in several companies in manufacturing and food production I see a familiar pattern. In the factories we have machines and applications that run production and generate sets of data. We create data pipelines to our data lake where we connect our DW and BI tools that analyze the business data.

The data mesh concept is designed to alter this architecture. It is a logical model that establishes core concepts around which we can build a data architecture. The data mesh has four principles:
- Domain-oriented decentralization
This means that each team owns their own data. We worked this way in the 1990s with the benefit that we had a close relationship to the data and could assess the quality and relevance of data quickly.
2. Data-as-a-product
Thinking of data as a product is useful as you as the product owner understand what data is relevant and where you find it. I spent months filtering data records for my own product before concluding on what we were going to use for the final release.
3. Self-serve data infrastructure
This one is difficult. The idea is that we have infrastructure in place, like a data store, where you can go and find the data you need without having to deal with a central data team. If you have programming skills or other tools, you can build and maintain your own products and have full control.
4. Federated governance
I believe this concept is the most radical in the data mesh concept. Instead of having company-wide central authority, the teams will collaborate and share best practices. Each team will retain decision-making power and control over their domain while collaborating and coordinating goals and shared resources with other teams.
The data mesh is a fresh concept that significantly differs from current theory. But there are significant challenges with this concept.
a. Data literacy: Collecting, using and owning your own data requires advanced skills that many employees don’t posess. Personally, I worked for one of the premier R&D companies in the world where everyone was comfortable working with data. While workers gain deep domain knowledge after working in a particular industry for a significant amount of time, they don’t develop data engineering or analytics skills needed.
b. Policy: One of the greatest challenges I see is the inability to follow the governance set by your company. It’s challenging with a central authority; distributed ownership will effectively end any adherence to a common governance policy.
c. Cost: A data mesh requires investment in people, infrastructure and applications to support the concept. Cost control is a killer of data science initiatives when results fail to materialize.
Alternatives to centralized and decentralized approaches
Data-as-a-service (DaaS) follows, at least in name, the trend in cloud services where ‘as a service’ is the key delivery concept. Enabled by Software as a Service (SaaS), DaaS delivers data on demand whenever the user needs it. Now we can bundle the data and the software needed to analyze into one package. But practicalities stand in the way of such an approach.
Transporting and storing data across borders presents challenges in security and privacy for many organizations. Locking data and software limits your ability to customize your data product. You are also limited to your provider and over time you risk your products being outdated and difficult to maintain.
Using a common platform to build your data products is still attractive as it combines elements from data warehouse and data lakes. Being focused on creating reusable products has several distinct advantages:
- Sharing high-volume data products is easy on a cloud-based platform
- You can enforce your data governance and security policies
- Consistency makes for reliable standardized data products
An alternative to DaaS is the ‘data hub.’ The data hub architecture provides a unified location for data access and integration like a traditional hub-and-spoke model. The goal is to simplify data management while improving consistency and quality. Better data visibility creates faster data delivery and real-time data updates.
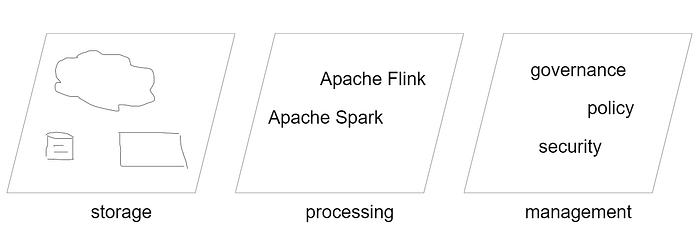
My own experience with hub-and-spoke is that it introduces organizational changes and issues of data ownership that recreates the problems encountered with traditional data warehouses and data lakes. The architecture is expensive and resource intensive and is best suited to solve high-impact problems to cover the cost of effort. What we have discovered is that both centralized and decentralized architectures present us with significant challenges that won’t be solved with technology.
What I would like to see is a solution that addresses domain-specific data products while we maintain central data governance, data consistency, and security across a large volume of data products.
Where are we going now?
The question I have been pondering is whether “the concept of microservices can be applied to data analytics as a reaction to big data and data lakes.” I believe ‘yes,’ but with a list of considerations and recommendations:
a. Develop a shared data infrastructure
The shared infrastructure should enable data ingestion, processing, and storage on a common platform with data-agnostic rules to enable product owners to focus on the development of their data products.
b. Implement central governance
Governance and policy safe guarding your data assets should be common for all data products. Encourage teams to collaborate to share best practices on how they implement and enforce policy.
c. Encourage domain-oriented ownership
Teams with domain knowledge should own their own data products and ensure the quality and usability of the product.
d. Facilitate data discovery and access
A portal with a searchable data catalog is needed to enable your users to discover and access data products from across the organization.
e. Monitor data consistency
Automate monitoring of data consistency and enable auditing to ensure that data products adhere to your governance and security policies.
Conclusion
Implementing the right framework for your data products, machine learning and artificial intelligence (AI) is a demanding task. It is likely that no single framework will fit your organization’s needs. What I propose is a federated data ecosystem that takes advantage of both centralized and decentralized data architecture approaches. Only careful analysis will reveal the unique qualities that will make your business become data driven.
Sources and further reading